

13 minutes

Most "VoC best practices" articles read like they were written by someone who has never operated one. They tell you to "listen to your customers" and "act on insights" as if those phrases are instructions. They aren't. They're the problem you're trying to solve.
This guide is the opposite. It's written for the operator who's been handed responsibility for a VoC program — either because nobody else owns it, or because what existed before isn't working — and needs to make specific decisions in the next 30 days.
A few framings before we start, because if these are wrong, everything downstream is wrong:
There is no single right way to run a VoC program. Anyone who tells you there is hasn't run one at multiple companies. The right shape depends on who owns it, how many customers you have, what your product is, and what decision-rights structure your org actually operates under (not the one on the org chart).
Most VoC programs fail the same way: not from collection, but from action. Teams obsess over surveys, channels, and tooling. The programs that produce business outcomes spend most of their effort downstream — on deduplication, prioritization, decision-making, and closing the loop. If you're reading this, you've probably already over-invested in collection. The bottleneck is somewhere else.
Maturity is not the same as automation. A mature program with manual tagging by a thoughtful operator beats an automated program with no operating discipline. Tooling is leverage on a working process, not a substitute for one. Don't buy software to fix a program you don't have yet.
With those out of the way, here's what we'll cover:
The five program archetypes — and how to pick yours
Building a taxonomy that survives past month six
ARR-weighted prioritization (and the math)
Signal deduplication at three different scales
Closing the loop — the practice most programs skip
A maturity model that gives you a self-assessment, not just a ladder
1. The five program archetypes
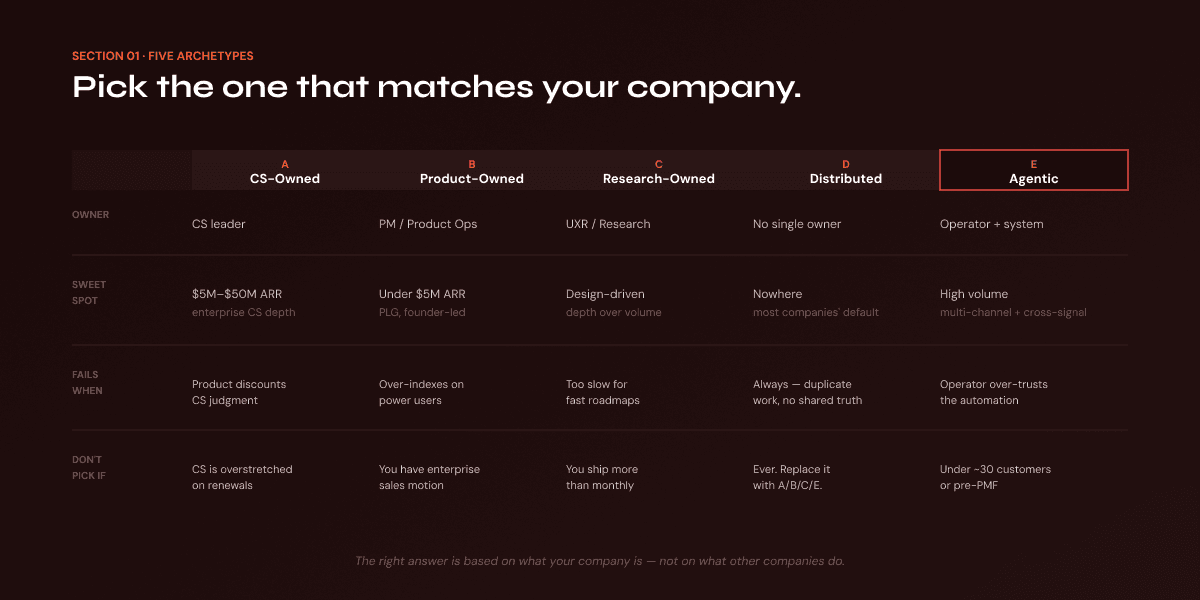
Most "how to structure VoC" content presents one model and calls it the right answer. The actual landscape has five real archetypes, each with honest trade-offs. Picking the wrong one for your stage is the most expensive mistake in this whole document.
Archetype A — Customer-Success-Owned
The CS team runs the program. Feedback flows in through CSMs, account reviews, and renewal conversations. The CS leader is the program owner; insights feed into product via a recurring meeting or shared backlog.
Where it works: Mid-stage B2B SaaS ($5M–$50M ARR) where CSMs already have deep account context. The signal quality is high because CSMs know which feedback is from a strategic account and which is from a noisy one.
Where it breaks: Product teams treat CS-curated feedback as second-hand and discount it. The CS-to-Product handoff becomes a political surface, not a process one. CS leaders are measured on retention, which biases the program toward at-risk accounts and away from greenfield opportunity signals.
Don't pick this if: Your CS team is overstretched on renewals, or your product team doesn't trust CS judgment.
Archetype B — Product-Owned
A PM, Head of Product, or Product Ops function owns the program directly. Feedback flows through tickets, in-app widgets, and product-led customer conversations.
Where it works: Product-led growth companies and early-stage startups (under ~$5M ARR) where the product team is the natural center of gravity. Decisions move fast because the people collecting feedback are the people building.
Where it breaks: Sales and CS feel cut out and start running shadow VoC programs in spreadsheets. The program over-indexes on power users and undercounts the silent majority. Sales objections from lost deals never make it into the system.
Don't pick this if: You have a significant enterprise sales motion, or your CS team has stronger customer relationships than your product team.
Archetype C — Research-Owned
UXR or Product Research owns the program. The dominant signal sources are interviews, usability studies, and structured research projects. Quantitative VoC sits alongside qualitative research.
Where it works: Design-driven companies, consumer products, and any environment where deep behavioral understanding matters more than feedback volume. Research-led programs produce the highest-quality individual insights.
Where it breaks: Slow. Volume is low. Engineering and product teams want answers in weeks; research-led programs deliver them in months. At companies where roadmaps move fast, research becomes "the team that wasn't consulted."
Don't pick this if: You ship more than monthly, or your product organization measures success in velocity.
Archetype D — Distributed (No Single Owner)
Multiple teams collect feedback independently. CS has a database. Product has a board. Sales has a CRM field. Support has a ticket category. There's no central program; there are many parallel programs.
Where it works: It doesn't, mostly. But it persists because every team has legitimate reasons to collect the feedback they collect, and forcing consolidation costs political capital.
Where it breaks: Everywhere. Duplicate work, conflicting taxonomies, no shared prioritization, no closing the loop. The same customer pain is recorded four times in four systems and acted on by none.
Don't pick this: This is the archetype most companies have by default, not by choice. If you're reading this guide, your job is probably to replace this with one of the other four.
Archetype E — Automated/Agentic
Software (whether traditional VoC tools or AI agents) handles collection, deduplication, tagging, and initial prioritization. A human operator reviews outputs, makes decisions, and owns the close-the-loop function. The platform does the work that doesn't require judgment; the human does the work that does.
Where it works: Companies with high feedback volume (a hundred-plus signals per week), multiple channels, and the discipline to act on what the system surfaces. Also companies where the cross-channel pattern matters as much as any single piece of feedback — including the overlap between customer voice and competitive signal.
Where it breaks: When operators trust the automation too much. Agentic systems can deduplicate and prioritize beautifully and still miss the one strategic signal that doesn't pattern-match to anything historical. The novel-and-important signal is exactly the one most likely to look like an outlier.
Don't pick this if: You have fewer than ~30 customers (you don't have enough volume to need automation, and direct founder-customer contact is more valuable than any aggregation). You're earlier than product-market fit (signals are too sparse and weighted toward early-adopter bias). Or you don't yet have an operator who'll act on what the system surfaces — automation amplifies whatever discipline already exists, and amplifying nothing is still nothing.
[IMAGE: archetype comparison table with the five archetypes as columns and characteristics — owner, sweet spot, primary failure mode — as rows]
How to actually pick
The choice usually comes down to two questions:
Where is your center of gravity? The team with the strongest customer relationships, the most cross-functional credibility, and the operating bandwidth to own a recurring program. That's your owner. If you're picking the team you wish owned it, you'll fail.
What's your scale? Under 30 customers — direct conversation, no program needed yet. 30–300 — Product- or CS-owned, manual or lightly tooled. 300–3,000 — increasingly hybrid; the volume forces structure. 3,000+ — either heavily resourced central team or automated/agentic, or both.
There is no archetype that's right for everyone. The mistake is picking based on what other companies do; the right answer is based on what your company is.
2. Building a taxonomy that survives past month six
Most VoC taxonomies fail within six months of launch. They were built once, by one team, in one workshop, and never updated. The product changed; the taxonomy didn't. New problems showed up that didn't fit existing categories, so people invented new categories ad-hoc, and the taxonomy fragmented. Within a year, nobody trusts the data because the categories don't mean what they used to.
The fix isn't a better taxonomy. The fix is a taxonomy practice.

Three taxonomy approaches
Top-down. A senior person designs the taxonomy upfront based on product structure, customer journey, or business strategy. Categories are imposed; data is tagged into them.
Strengths: Fast to launch. Aligned to how leadership thinks. Weaknesses: Misses signals that don't fit the categories the designer imagined. Calcifies quickly.
Bottom-up. Categories emerge from the data. You start by tagging individual feedback with descriptive labels, then cluster similar labels into themes, then promote themes into taxonomy categories.
Strengths: The taxonomy reflects what customers actually say, not what you assumed they'd say. Weaknesses: Slow. Requires significant volume before patterns emerge. Hard to use in week one.
Hybrid (the one that works). Start top-down with a small, stable spine — usually 6–10 top-level categories tied to product areas or customer outcomes. Allow bottom-up sub-categories underneath, with a quarterly review that promotes recurring sub-categories into the spine or retires unused ones.
The hybrid model is the only one that survives. Pure top-down dies of irrelevance; pure bottom-up dies of inconsistency. Hybrid dies if you skip the quarterly review, but otherwise persists.
[IMAGE: three-column comparison of the taxonomy approaches with structural diagrams]
The "stable spine" rule
Whatever your top-level taxonomy is, it should change rarely — at most once a quarter, and ideally less. Sub-categories can move freely. The discipline is: changes to the spine require a deliberate decision; changes below the spine don't.
If you can't tell someone "here's our top-level taxonomy and it's the same as it was last quarter," your data isn't comparable over time, and you can't track whether your interventions are working.
Why most taxonomies fragment
The single most common failure pattern: someone adds a new category mid-quarter because the existing ones "didn't fit." Six months later, there are 47 categories, three of which are near-duplicates of each other. The data is uncomparable, the dashboard is unusable, and the team quietly stops tagging.
The discipline: new top-level categories require approval. Sub-categories are free. Tagging into "Other" is allowed and tracked — when "Other" exceeds 15% of recent feedback, that's the signal to update the taxonomy.
3. ARR-weighted prioritization (and the math)
Most VoC programs prioritize by ticket count. A request from 50 customers ranks higher than a request from 5. This is the move that separates programs that drive business outcomes from programs that produce reports.
The fix is to weight by revenue.

The basic formula
For any feedback theme, calculate a priority score as:
Where:
ΣARR is the sum of annual recurring revenue from customers who raised the theme. Not the count of customers — the revenue.
Frequency is the number of distinct customers who raised it (with diminishing returns — see below).
Strategic Fit is a 0.5–1.5 multiplier reflecting how well the theme aligns with current product strategy. 1.0 is neutral; below 1.0 deprioritizes; above 1.0 amplifies.
A worked example
Consider three themes:
Theme A: Requested by 47 customers, totaling $180K ARR. Strategic fit: 0.8 (adjacent to strategy, not core). Score: $180K × 47 × 0.8 = $6.77M (in arbitrary score units)
Theme B: Requested by 8 customers, totaling $1.2M ARR. Strategic fit: 1.3 (highly aligned with strategy). Score: $1.2M × 8 × 1.3 = $12.48M
Theme C: Requested by 22 customers, totaling $640K ARR. Strategic fit: 1.0. Score: $640K × 22 × 1.0 = $14.08M
Pure ticket-counting would rank A > C > B. ARR-weighted prioritization ranks C > B > A. The "loudest" theme isn't the most valuable.
The diminishing-returns adjustment
In practice, raw frequency over-weights themes that come from large customer bases. A more honest formula uses log-scale frequency:
This is the formula mature programs converge to. It rewards breadth without letting one theme dominate just because it's high-volume.
What the formula doesn't do
It doesn't tell you to build the highest-scoring theme. It tells you which theme deserves the next round of discovery. The score is an input to a decision, not a decision. A theme that scores 3× another might still lose because the engineering cost is 10× or because it conflicts with strategic direction in a way the multiplier didn't capture.
The value of the formula isn't precision — it's that it forces the prioritization conversation to be about the right things. When sales argues "this enterprise account is asking for X," the ARR-weighting puts that argument on the same axis as everything else.
[IMAGE: visualization of the three-theme example showing ticket-count ranking vs ARR-weighted ranking]
A caveat that matters
ARR-weighting is honest math, but it bakes in a strategic assumption: that you should prioritize what your current paying customers want. For early-stage products trying to expand into new segments, this is exactly backwards — the new segment is by definition under-represented in current ARR. For those companies, the formula needs a second weighting layer for "strategic-segment fit," or you need to run two parallel prioritization queues (existing customers and target customers) and synthesize across them.
4. Signal deduplication at three different scales
This is the operational discipline that most distinguishes mature programs from immature ones. It's also the most invisible work, which is why most programs neglect it.
The core problem: 100 feature requests are usually 8–12 underlying needs. The same customer pain shows up with different wording, different framings, different specifics. "I want a CSV export" and "Can we get the data into Excel" and "I need to share these numbers with finance" might be three flavors of the same underlying need — or three different needs that happen to share surface language. Telling them apart is the work.
How you do this depends entirely on scale.

Under 50 customers — Manual tagging
One operator (often the founder or first PM) reviews each piece of feedback and assigns tags. The operator's memory does the deduplication: "I've seen this before from Customer X — same theme."
This works because the human can hold the full feedback history in their head. It also doesn't scale past about 50 customers, when the memory model breaks.
Operating discipline: Review queue once a day. Tag, cluster, link related items. Maintain a "themes I'm watching" document with 10–20 active themes and which customers contributed to each.
Common failure: The operator leaves or gets reassigned. The institutional knowledge dies with them. Documentation becomes the antidote.
50–500 customers — Semi-automated
The operator can no longer remember everything. Tooling enters: keyword tagging rules, similarity search across existing themes, AI-assisted clustering with human review.
The pattern that works: tools surface candidate matches ("this new feedback looks similar to existing themes A, C, F — which is it?") and humans confirm or reject. The human stays in the loop on the categorization decision, but the surfacing of candidates is automated.
Operating discipline: Weekly clustering review. Take all new feedback from the week, run similarity matching against existing themes, manually confirm assignments for the ambiguous ones, create new themes where genuinely warranted.
Common failure: Operators over-trust the automated matching and silently allow themes to drift. Cure: every quarter, a human reads a sample of the auto-tagged data and audits the assignments.
500+ customers — Agentic
At scale, no human reviews every piece of feedback. Agents handle ingestion, clustering, and deduplication continuously, surfacing themes and changes to themes for human review. The human's job shifts from tagging to governing the system that tags.
This is where the operating model changes most. The discipline isn't "review every signal" — it's "review the cluster definitions, sample the assignments, and intervene when the system surfaces something the rules can't categorize."
Operating discipline: Daily review of system-flagged anomalies. Weekly review of theme-level changes. Monthly governance review of taxonomy and clustering rules. Quarterly audit by a different team to catch systemic biases.
Common failure: Treating the agentic system as a black box. The operator stops being able to explain why a particular theme ranks where it does. When the CEO asks "why is X our top priority," nobody can answer without re-running the analysis. Cure: every theme that reaches the priority list must have a traceable explanation.
[IMAGE: scale-vs-method diagram showing the three operating models with characteristic signal volumes]
The cross-cutting truth
At every scale, the deduplication discipline matters more than the tagging discipline. A program that perfectly tags duplicated feedback is still a program that double-counts. The bottleneck is collapsing variants of the same need into one canonical theme, not labeling each variant precisely.
5. Closing the loop: the practice most programs skip
If you do nothing else from this guide, do this.
Closing the loop means going back to the customer who gave you feedback and telling them what happened. Not "thanks for your input," which doesn't count. Specifically: "you told us X; here's what we did about it / here's why we're not doing it / here's the timeline we're committing to."
Multiple vendor studies (with the standard caveat that they're directional, not academic) consistently find that programs which close the loop reduce churn by 2–3 percentage points compared to programs that don't. The 2.3% figure from CustomerGauge research is the most-cited number; it appears across enough independent sources to suggest the direction is real even if the precision is questionable.
But the bigger reason matters more than the churn math: customers who get a closed loop give you better feedback next time. They learn that telling you things changes things. Programs that close the loop get higher-quality feedback over the years; programs that don't end up with declining response rates and increasingly vague input.
Why most programs skip it
Closing the loop is operationally expensive. It requires going back to a specific customer, telling them a specific thing, often months after they raised the feedback, sometimes telling them the answer is no. None of this scales nicely. Most programs collect at industrial scale and then quietly drop the close-the-loop step because nobody's measured on it.
What good looks like
The mature pattern: every theme that reaches the priority queue has owned communication outcomes attached. When the theme is built, a list of contributing customers gets a specific message. When the theme is deprioritized, the same list gets a different specific message. The default isn't silence — silence is the failure mode.
The mechanism doesn't have to be heavy. A monthly "you said, we did" email to the customers who contributed to shipped themes is a defensible minimum. CSMs delivering the message in account reviews is better. A public changelog with explicit credit ("this came from customer feedback we received in Q3") is best, because it creates a public commitment that compounds.
The honest constraint
Closing the loop on negative outcomes — telling customers "we heard you and we're not going to do this" — is harder than closing the loop on positive ones. Most programs that "close the loop" only do so on themes they ship. The mature version closes the loop on deprioritizations too. This is uncomfortable and most teams skip it. It's also the thing that distinguishes a real VoC program from a marketing veneer of one.
6. A maturity model that gives you a self-assessment
Most maturity models are decorative. They give you levels with abstract names ("ad-hoc → defined → managed → optimized") that nobody can actually self-assess against. The version below is built around specific, observable operating characteristics. If you can answer the questions, you know what level you're at.
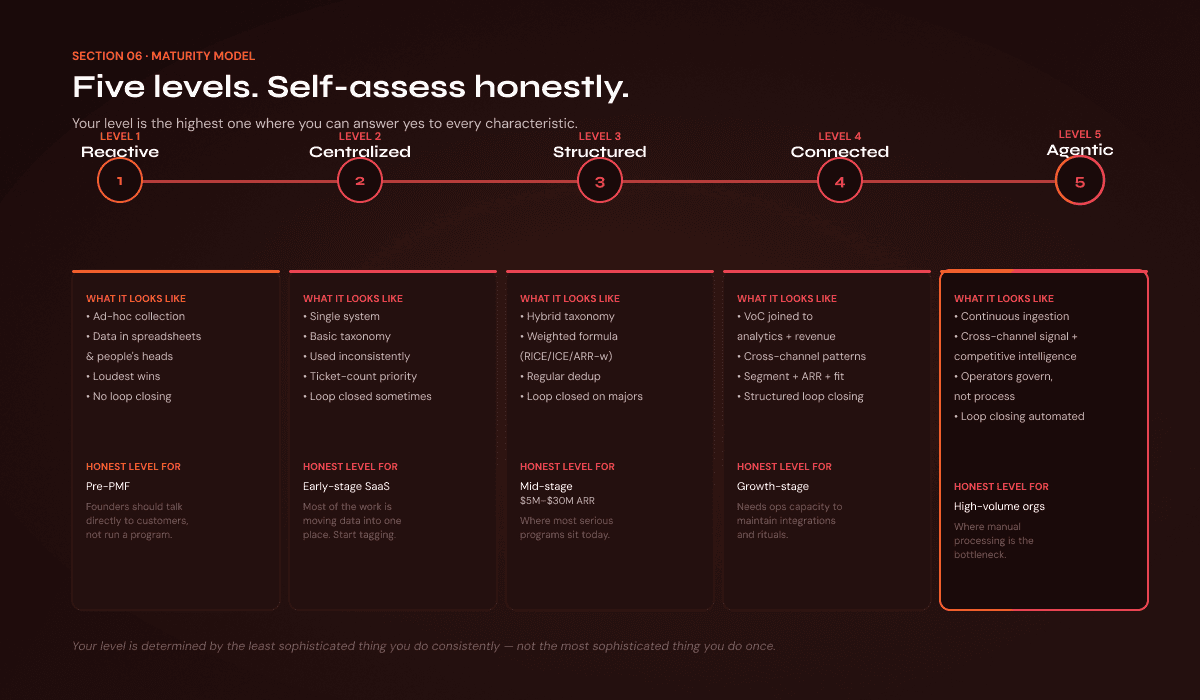
Level 1 — Reactive
Feedback is collected when someone happens to ask for it
No single system holds the data; it lives in tickets, spreadsheets, and people's heads
"Priority" is determined by who shouts loudest
No closing the loop
The honest level for: Pre-product-market-fit companies. Founders should be talking directly to customers, not running a program.
Level 2 — Centralized
Feedback is captured in a single system across multiple channels
A basic taxonomy exists; it's used inconsistently
Prioritization is by ticket count or executive opinion
Closing the loop happens occasionally, usually for sales reasons
The honest level for: Early-stage SaaS getting its first VoC discipline. Most of the work is moving data into one place and starting to tag.
Level 3 — Structured
Hybrid taxonomy with a stable spine and active sub-categories
Prioritization uses a weighted formula (RICE, ICE, or ARR-weighted)
Deduplication is a regular operating practice
Closing the loop happens for major shipped themes
The honest level for: Mid-stage SaaS ($5M–$30M ARR). This is where most companies with serious VoC programs sit. The leap from Level 2 to Level 3 is mostly operational discipline, not tooling.
Level 4 — Connected
VoC signal is joined to product analytics, churn data, and revenue
Cross-channel patterns are detected (support + sales + reviews showing the same theme)
Prioritization explicitly considers segment, ARR, and strategic fit
Closing the loop is structured (monthly customer communications, public changelog with feedback attribution)
The honest level for: Growth-stage companies with the operations capacity to maintain integrations and the management discipline to maintain rituals.
Level 5 — Agentic
Continuous, automated ingestion and clustering across all channels
Cross-channel signal joining including competitive intelligence (the wedge most programs miss)
Human operators govern the system rather than process individual signals
Closing the loop is automated where appropriate, escalated where not
The program produces insights at a cadence the rest of the company can act on
The honest level for: Companies whose feedback volume, channel breadth, and operating tempo make manual processing the bottleneck. Not most companies.
[IMAGE: maturity model diagram showing the five levels with the operating characteristics that distinguish each]
How to use this honestly
Your level isn't determined by the most sophisticated thing you do. It's determined by the least sophisticated thing you do consistently. A program with brilliant cross-channel analysis but no taxonomy discipline is Level 2 with delusions, not Level 4. The honest self-assessment is: what's the highest level where you can answer yes to every bullet?
Most companies that think they're at Level 4 are at Level 2 or 3. The acceleration from Level 2 to Level 3 — taxonomy discipline, weighted prioritization, regular deduplication, partial close-the-loop — is the highest-ROI investment in this whole document. It produces more business outcome than any tooling decision.

Conclusion
What to do in your first 30 days
If you've inherited a VoC program (or been asked to build one), here's the operating sequence:
Days 1–7: Pick your archetype. Use the framework in Section 1. Get explicit agreement from whoever needs to agree. Don't proceed without ownership clarity — every later step depends on it.
Days 8–14: Audit what exists. Where is feedback already being collected? By whom? In what systems? Map the ground truth, not the org chart. You'll find more parallel programs than you expected.
Days 15–21: Build the stable spine. Six to ten top-level taxonomy categories tied to product areas or customer outcomes. Don't aim for completeness; aim for stability.
Days 22–28: Set the prioritization formula. ARR-weighted, weighted scoring, or RICE — pick one, document it, get sign-off. Run it on three live themes to show how it works.
Days 29–30: Close one loop. Pick one theme that's been raised by multiple customers and ship a closing-the-loop message — even if it's a "here's where we are, here's what we're doing" message rather than a "we shipped it" message. The discipline starts on day 30, not month 12.



